Recently, my team from UNC-Chapel Hill won an F1/Tenth competition, held at CPSWeek 2019, in Montreal. For those who don't know, F1/Tenth is an autonomous R/C car race with an emphasis primarily on a common platform--so competition is primarily between algorithms and less about the quality of the physical vehicle. I encourage anyone interested to check out the F1Tenth Website for more information.
To the surprise of myself and my teammates, not only did our car win, but it won by a wide margin, even beating out the contest organizers! Among the cars able to reliably complete laps at the event, only two apart from ours were able to do so at a high speed. Both of these teams (as far as I know) were doing some combination of localization and path optimization. One of them, from the University of Modena, completed laps of the ~150 foot track in around 14.7 seconds. The other team was the contest organizers, from Penn, and they completed laps in around 12.7 seconds. (I'll also note that after increasing their speed in order to accomplish these times, neither of these cars completed all four minutes of the time-trials with no accidents.) Team UNC's lap time: ~11.5 seconds! And no crashes whatsoever during any of the 11 total minutes of time trials!
It was apparent to anybody present at the competition that both of the runner-up teams were running elegant code with good, smooth controls, leading to their cars taking a safe-looking but short path around the track. I even felt a bit guilty that our car was able to win against these teams who had clearly put far more thought and care into developing an algorithm that not only runs a track, but also could, unlike ours, legitimately further the field of autonomous driving.
But, rules are rules, and the rules of the event were just to complete laps as fast as possible!
So, on to answer the real question: what algorithm did we use to win? Essentially, our algorithm was: follow the shortest safe path through the track, and drive as quickly as possible. This sounds obvious, but it's still relevant--the biggest differentiator between "Team UNC" and Penn or Modena was the fact that the latter two visibly diverged from the shortest path at several points around the track. Both were going fast, but with ~150ft of track and a near-identical top speed for all of our cars, the slight path differences were enough to give us the second or two of an edge on each lap--adding up to quite a few more laps over the span of several minutes.
So, clearly I was happy with our performance, but why do I think other teams should care?
Several teams at the event were doing some simpler algorithms, namely some variants of wall following, center-of-track following, or "gap finding". Our algorithm is not only faster than any of these, it is also simpler and more robust (in my opinion--there are of course situations that our algorithm doesn't handle properly, which I'll cover in later paragraphs). I honestly believe that, barring major changes to the contest track or format, our algorithm can and should represent a new baseline for every team from now on. At the very least, any team looking to ditch wall-following, gap finding, etc., and instead use a simple, competitive solution should check this out.
The remainder of this essay will be as follows:
I'll start by summarizing the algorithm in a nutshell. At every instant:
The first of these two steps is the one that bears more explaining. First, we assume that the car is regularly receiving data from a LIDAR sensor, which will simply be an array of distances (once again, see the F1Tenth website at the top of this article if you don't know what I'm talking about here). Finding the longest distance in an array of distances is trivial, and we can figure out the angle where this distance appears and drive towards it. For example, see this image:
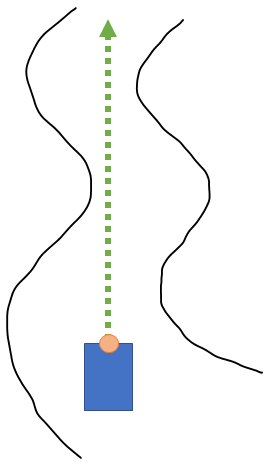
(For the rest of this article, I am just taking for granted that if the angle exceeds the car's steering angle that we just turn as sharply as possible towards the correct angle.)
However, there's a problem with this that quickly becomes apparent: the LIDAR "thinks" of itself as a single point, but in reality it's on a car that has some width. Driving towards the most distant point may cause the wheels and sides of the car to crash into corners or other obstacles, despite the fact that the point is visible. If we followed the path in the first image, we would crash at this point:
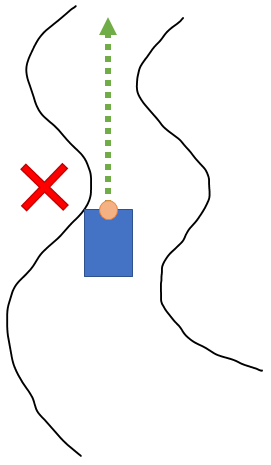
So, how do we account for this?
We did so by using an algorithm to produce a "filtered" list of distance samples, where each distance in the filtered list corresponds to a distance that's safely reachable by driving in a straight line. Hopefully this makes it obvious why we call our driving approach the "disparity extender" algorithm:
The array of samples now contains only safely-reachable distances. Search through these filtered distances corresponding to angles between -90 and +90 degrees (to make sure we don't identify a path behind the car). Once you find the sample with the farthest distance in this range, calculate the corresponding angle--that's the direction you want to target.
The key insight behind this algorithm is that the obstacles that intrude into the path of the car will result in a "disparity" in the LIDAR data. Here, we use "disparity" to refer to two subsequent points in the array of distance values that differ by some amount larger than some predefined threshold. This threshold doesn't need to be very large--there will be only 4 or 5 centimeters between LIDAR samples (using the F1/Tenth-recommended LIDAR) at 7-8 meters, which is a pretty long distance at the scale of these cars. So, using a threshold of 0.1 or 0.2 meters for identifying a "disparity" between subsequent LIDAR readings should be good enough for any practical purposes.
Here are a summary of the above steps using pictures.
Step 2: Finding a disparity: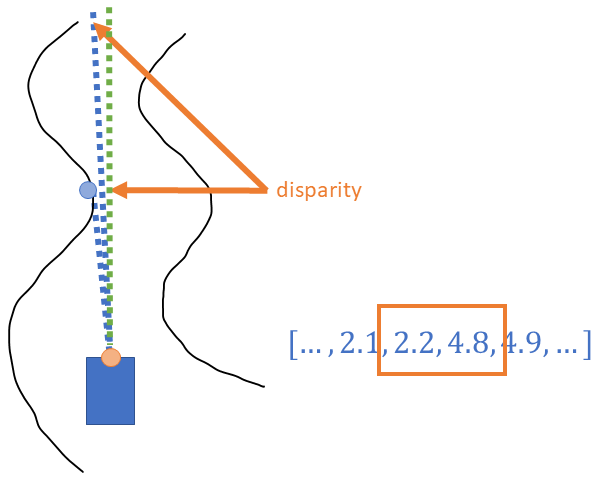 Step 3: Overwriting LIDAR readings equal to the car's width plus some tolerance
at the disparity point ("extend the disparity").
Step 3: Overwriting LIDAR readings equal to the car's width plus some tolerance
at the disparity point ("extend the disparity").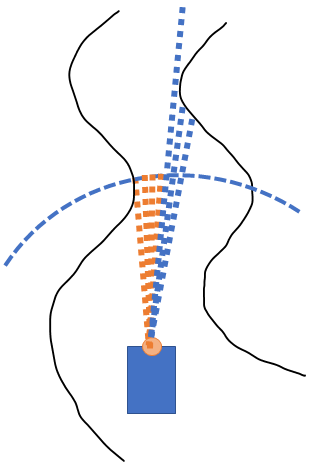 We mask over LIDAR readings (shown in orange) in order to make them appear shorter in the "filtered" array--these should approximate points that the car can actually reach.
Step 3 (continued): Repeat this process for every disparity, but never
overwrite closer "distances" with farther ones.
We mask over LIDAR readings (shown in orange) in order to make them appear shorter in the "filtered" array--these should approximate points that the car can actually reach.
Step 3 (continued): Repeat this process for every disparity, but never
overwrite closer "distances" with farther ones.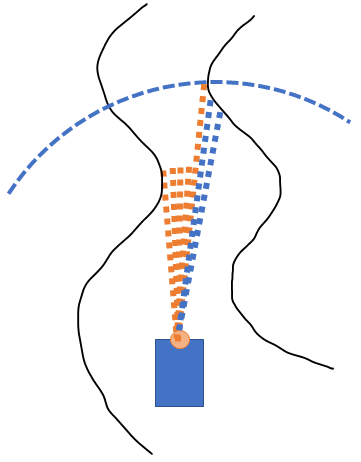 Step 4: Find the farthest reachable distance in the new list of distances, and
use that as the target direction.
Step 4: Find the farthest reachable distance in the new list of distances, and
use that as the target direction.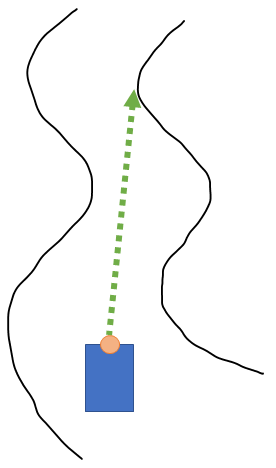
As I'll argue later, this algorithm is sufficient for "finding the shortest path" through the track. Our system for "drive as fast as possible" is even less sophisticated, but, in our experience, quite effective. We pick a speed based solely on the forward distance--the free space directly in front of the car. If this distance is long enough, we drive at the car's maximum speed. If it's too short for the car to turn or avoid a collision, then we stop.
If the forward distance is anywhere in between the minimum safe distance and the safe "full-speed" distance, then we simply scale the speed based on the distance. We used a simple linear-scaling approach along two segments, but this can easily be adjusted to use non-linear functions of distance should someone else choose to do so. As for why I think it's okay to scale speed using forward distance alone:
There are only two reasons for the car to slow down:
Of these, reason 2 is less important under our assumptions, because our algorithm is easily fast enough to keep up with the LIDAR's 40Hz frame rate, even when implemented in pure Python. (There are edge cases I'll discuss later where this isn't quite true.)
Reason 1 (don't flip over) is handled fairly well by the forward-distance approach to scaling speed--after all, this only applies when you're making a turn. If you're making a turn you've either seen the turn from a long way away or suddenly encountered it. If you saw the turn from a long way away, that likely means that it's a gentle turn so the car is perfectly fine to continue moving quickly. If the turn approached quickly, then the car should have been already facing a wall when it encountered a turn, so it would have slowed down like it's supposed to.
The one possible "incorrect" point here is if the car rounds a turn and suddenly encounters a very wide area where the longest path is still sharply in one direction. However, as long as the car doesn't flip over, it's perfectly safe for it to "drift" in such a case--after all, the only reason it's going fast is because it's already determined that there's adequate space. One may argue that a car that's drifting is moving less efficiently--but on the other hand why would you want to stop your RC car from drifting at high speeds when it's so cool?
Even though the algorithm as described above adequately accounts for the width of the car, we need to tack on one additional constraint to make sure the rear of the car doesn't strike a corner (or passing car) when trying to turn. We handled this case in a very simple manner that simply assumes that whatever obstacle is at the side of the car is not moving towards the car. (We're assuming that the LIDAR is mounted on the front of the car). The tweak is like this:
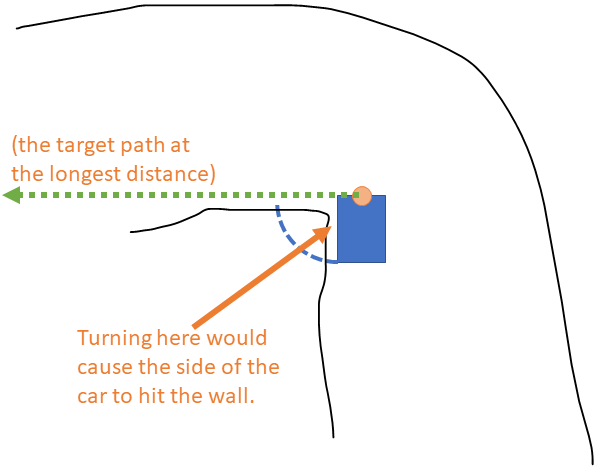 This is a situation where we would make the car continue to drive straight, even though it "wants" to turn left.
This is a situation where we would make the car continue to drive straight, even though it "wants" to turn left.
Overall, this algorithm is very reactive--the most compute-intensive portions are scanning the LIDAR array for disparities and extending the disparities; the latter of which is only proportional to the number of disparities identified. It requires no trignometric operations or fancy math, is resilient to noise (it may cause some "twitchy" steering, but will quickly self-correct), and is capable of dodging obstacles out-of-the-box.
Later on, I will attempt to argue that this greedy algorithm correctly follows the shortest path, based on a set of assumptions that I believe are reasonable for F1/Tenth races. However, first I will give discuss a case we've identified where the algorithm can fail.
With careful tolerances this algorithm should never allow the car to crash into an obstacle that it's able to see, but it has another failure condition: under some situations, it will try to perform a U-Turn (even though this is arguably safe behavior, it's definitely not conducive to winning races).
Specifically, a U-turn happens in situations like the following, where the car is on the inside corner of a wide portion of track, and must turn into a narrower portion of track:
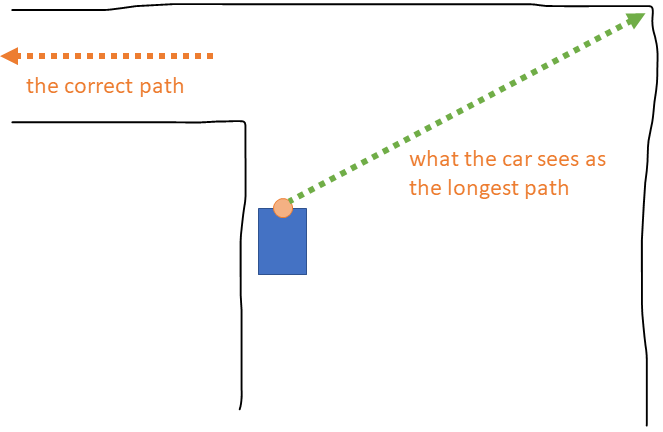
The problem occurs because, as the car approaches the turn, it will be able to "see" some reachable paths into the turn. However, these paths will be shorter than the paths to the side--into the wide part of the track the car is already in. The car would see the correct path if it moved forward slightly more:
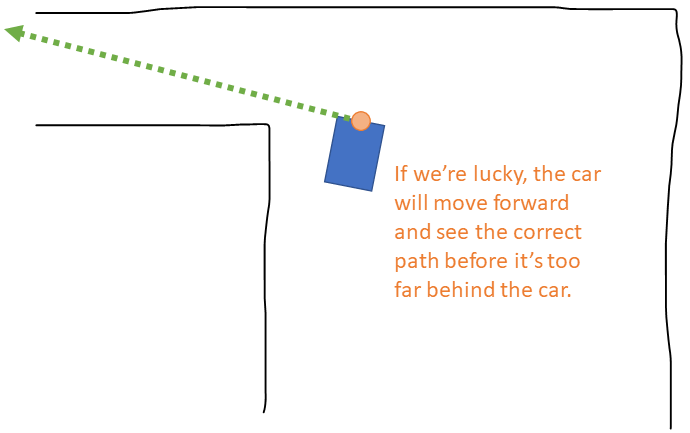
However, by the time it's far enough forward it may already have turned too much, leaving the correct path behind the car rather than to the right or left of it:
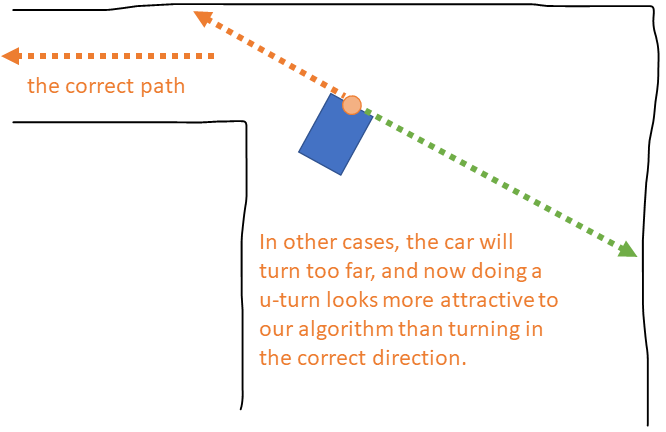
This issue shouldn't occur on any track with a uniform width, because any portion of track that the car must turn towards will always be the same width as the portion of track the car is already on--so the opposite wall of the current portion of track will never be the farthest reachable distance.
Overall, however, we did not encounter this problem at the F1/Tenth contest at CPSWeek 2019, but that may change in the future, especially if the contest organizers build a track specifically to exploit this issue, or if there are more races against other cars or dynamic obstacles.
So, my conclusion is that this problem needs addressing, but I hope it's something we can just detect and avoid. I think the best way forward is to integrate better path-planning or dynamic mapping into our base algorithm, to hopefully maintain the benefits of the algorithm in general while avoiding pitfalls like this one.
And, for those who want a video of the problem in action, here's one where I stand in front of the car at a specific point at the F1/Tenth contest track:
As mentioned earlier, I will now spend the rest of this article arguing that this simple algorithm correctly follows the shortest path around a track under some ideal assumptions, and does very good job at approximating the path in most cases.
My first claim is that the "optimal" way to drive around around an ideal uniform-width track is to take the shortest path, as fast as possible. We can actually restate this definition as something more helpful. If a car is taking the optimal path, then during every time instant, the car makes as much progress as possible around the track. In this sense, "as much progress as possible" really means "reducing the distance to the end of the lap/track as much as possible."
First, let's re-visit the notion of "going in the direction of the longest safe straight-line distance." With the above definition of "optimal", it becomes a bit more clear why this simple rule is the optimal strategy. At a given instant, under our assumptions, the longest straight-line path in a forward direction is also the path that covers the most track--in short, it's the direction that makes the most possible progress towards completing a lap!
But what about places where the longest forward distance ends up targeting a point that's clearly outside of the best possible path, like at a U-bend:
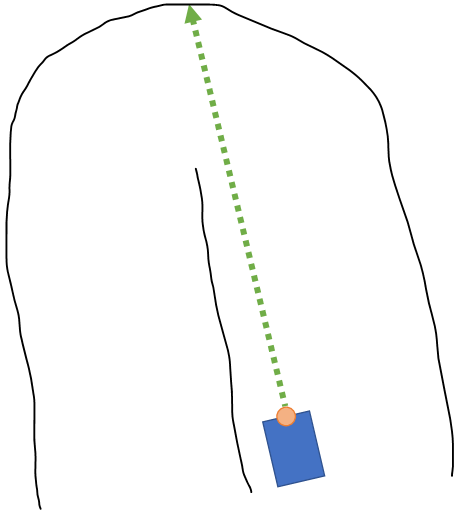 The car's approximate target path at a U-bend in a uniform-width track (drawn by hand, so just assume it's uniform width!)
The car's approximate target path at a U-bend in a uniform-width track (drawn by hand, so just assume it's uniform width!)
The car is trying to drive towards the farthest point in that elbow--clearly that point is far from the optimal path, right? However, on an ideal track, this isn't relevant, because at the instant that the car identifies this longest path, it is still the path that covers the most track. The fact that it's in the (slightly) wrong ultimate direction doesn't matter--and furthermore when the car reaches the point where it can "see" around the elbow, it will choose a new path anyway. (If you're still not intuitively convinced, try tracing the shortest safe path from the car's position to around the bend in the figure above--the car's initial target direction should be the same as the direction indicated in the figure.)
So, that's the general argument for why the algorithm attempts to follow the shortest path, but what about the fastest speed? Under the ideal assumptions outlined above, speed is irrelevant because sensing, reaction, and physical characteristics of the car are perfect, meaning the ideal car should be moving at the maximum speed constantly. However, I'll break from the purely ideal scenario here because speed plays an important role in many aspects of the algorithm's performance in reality.
Fortunately, the seemingly over-simple "forward-distance" method for scaling speed turns out to have great synergy with our particular algorithm. The reason for this is simple: our algorithm is constantly trying to maximize forward distance! In short, if we're not in a position where we can move at the fastest possible speed, we are actively working to re-establish such a position as soon as possible.
My team and I had a great time at the competition, and I would certainly enjoy returning and seeing participation increase. I was slightly surprised that only seven teams participated (including Penn, who helped organize the contest, so I'm not sure if they count as true "participants"). So, in the hopes of encouraging more teams considering entering to bite the bullet and actually participate, I'll conclude with a story about how our team was started, and how we developed the winning algorithm.
First off, my team was formed in a rather impromptu fashion, after Professor Duggirala joined the computer science department at UNC. When he joined, I was one of a small handful of students who had worked before with the F1/Tenth platform as part of a small experimental class, so I was invited to join the newly-formed UNC team for the F1/Tenth competition.
A few weeks later, our team had met a few times, and managed to assemble a car. Sort of. It ended up taking us another couple weeks before we had figured out all of the "nuts-and-bolts" problems like configuring our motor controller correctly, figuring out how to actually get the steering servo on our our motor controller to engage (if you've been in this situation as somebody who has little experience working with this kind of stuff, you'll know how frustrating it can be), configuring an ad-hoc wifi network for the car, and so on. The point is, that we didn't have a car that could move at all until nearly three weeks before the competition.
At that point, we had a car that moved, but our ability to reliably complete laps was questionable, much less its ability to do so quickly. Around this time, we held a meeting on a Saturday, ostensibly to "test" the car, but we had no code worth testing yet! As group meetings often go, this meeting was full of several good ideas, but not much code actually being written for them. I suggested that we should start with something based solely on how simple it would be to implement, and then work up from there. The simplest thing I could think of was the "find the farthest distance" algorithm I listed above, and later that evening that I thought of the "disparity extender" portion of it for efficiently navigating around obstacles.
After testing this algorithm on small tracks around our department, we were convinced that it was pretty good, despite occasional U-Turns. Ultimately, efforts made by other team members to implement a more sophisticated algorithm weren't finished in time for the competition, so we headed to Montreal intending mostly to see what we could do with what we had--we had no idea how our simple code would fare in the competition. So, we were quite surprised when we tested the car on the competition track and proceeded to win with virtually no changes necessary! It was only after this, while questioning what made our approach so effective, that I came up with the arguments I outlined above.
So, to any teams out there who think that they can't or shouldn't compete because they don't have a specialist in computer vision, path planning, robotics, or control theory, my message is that you don't need that stuff! You're not trying to build a fleet of self-driving taxis--you just need to get an R/C car to drive itself around a track. And, if you're just beginning, there's a simple but effective algorithm I'd recommend starting with!
To finish up, I also want to give credit to the rest of my team, including Charlotte, who helped with fabricating parts, car assembly, and testing, Tanya, who helped with math, wrote most of the speed-control code, and designed the pictures in this article, Abel, who spent many hours with and without me trying to get the car to work and who continues to work to improve the algorithm, and Professor Duggirala who directed this project with the liberating command: "I don't care about the car's safety if going slow is just going to make you lose."
 From left to right: Me, Charlotte, Professor Sridhar Duggirala, Tanya, and Abel
From left to right: Me, Charlotte, Professor Sridhar Duggirala, Tanya, and Abel
Also, thank you to the folks on the Penn team who were willing to chat with us at the contest, and who were good sports about our car rear-ending them at high speed during head-to-head skirmishes!